Dragon Voice features
Dragon Voice provides raw recognition as well as a rich conversational voice experience by leveraging AI-based speech technology to support a more natural, open-dialog flow.
| Main features | For information |
|---|---|
| Raw recognition of spoken words | See Krypton-only recognition. |
|
Natural conversations |
See Semantic interpretation. |
| Data packs, semantic and linguistic, and dynamic wordsets | See Engine models for accuracy and intelligence. |
| Starter packs to accelerate application development | See Starter packs to speed development. |
| Custom pronunciations for specific environments | See Custom pronunciations. |
Krypton-only recognition
The Krypton-only recognition feature provides raw recognition. It returns the words spoken in the audio.

- The application loads any needed linguistic models and wordsets, and then streams audio (speech) and triggers a recognition.
- The audio passes through the Nuance Speech Server, the Natural Language Processing service, and the Krypton recognition engine.
- Speech Server passes the result to the voice browser.
What you need to know:
- To enable Krypton-only, you must configure nlps-audio-only or server.nlps.audioOnly.
- To deploy Krypton-only,see Deployment architecture decisions.
- To understand the recognition dataflow, see Dragon Voice recognition flow.
- To prepare your application, see VoiceXML application structure.
- To prepare for recognition, see Triggering the Dragon Voice recognizer.
- To understand the recognition results, see Getting recognition results.
Semantic interpretation
Dragon Voice engines can extract intentions and entities (and values) from caller requests. This enables your applications to conduct highly intelligent, contextually aware, and natural conversational experiences.
For example, to understand what a caller wants to accomplish by what he or she says:
- Speech (audio) is streamed by the Nuance Speech Server to the Krypton recognition engine (via the Natural Language Processing service, which manages the connections between Speech Server and Dragon Voice engines).
- The Krypton engine sends the ensuing recognition result to the Natural Language Engine (NLE) for semantic processing (again via the Natural Language Processing service).
- NLE receives the result from Krypton and sends the top interpretation to NTpE for tokenization.
- NTpE feeds the resulting token sequence to NLE.
- NLE, in turn, returns the semantic results—the spoken intent and any entities (also known as "concepts," “slots,” or “mentions”)—as a text result back to the Speech Server (via the Natural Language Processing service).
- Speech Server passes the result to the voice browser.
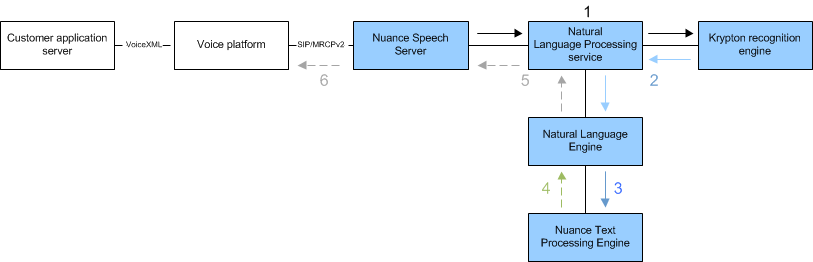
By chaining the processing of these engines together, more accurate recognition and interpretation results are achieved.
Engine models for accuracy and intelligence
As input, each of the core engines requires a set of models to accomplish its tasks. The models dictate how to manipulate and understand the input to each service. In effect, the input is layered from general understandings to more specific or specialized information geared to the end user.
- Some models provide a capability that is general to all applications, while other models provide a focus specific to an application.
- You can download default models with general capabilities from Nuance Network, and you can generate custom models with specific capabilities using Nuance Experience Studio or Nuance Mix Tools. Speak to your Nuance sales representative about obtaining access to either of those tools.
At startup the Krypton engine initializes itself with a factory or base data pack that you can download from Nuance Network. Each data pack provides a base language model that enables Krypton to recognize and transcribe the most common terms and constructs in the language and locale. You may complement this base language model by creating a custom model for a specific application or domain, called a domain language model (DLM), using Nuance Experience Studio.
A data pack includes, among other data files:
- Acoustic model: Statistical model that allows the system to translate utterances into phonetic representations of speech. Used to map sound to a word or words.
- Language model: Statistical model for the syntax of language constructs. Used to identify the words or phrases most likely spoken.
A data pack may also support multiple builtins and verticals. Builtins are recognition objects that are focused on common tasks (numbers, dates, and so on). Verticals provide a specialized, yet still general, knowledge of a domain (such as the banking domain or the retail domain). Each recognition turn can leverage a specialized weighted mix of builtins, verticals, DLMs, and application-generated wordsets.
The Nuance Text Processing Engine and Krypton use the same data pack. Whereas Krypton uses both the acoustic model and the language model, NTpE uses only the language model.
You can complement the factory data pack with multiple domain language models (DLMs). These are custom models that you generate with Nuance Experience Studio or Nuance Mix Tools. In addition, NTpE requires an application linguistic model (ALM), which is packaged inside the semantic model generated by those tools. The ALM includes the extra vocabulary and text transformation rules specific to a customer’s application domain.
The data fill for Krypton and NTpE, therefore, is the combination of a cross-application language model (data pack) and the application-specific content (DLMs and ALM) used to specialize speech recognition and text processing for a specific application. Optional wordset files, which are used by Krypton (and NLE) to specialize the vocabulary at runtime, are therefore also considered recognition objects.
The Natural Language Engine (NLE) consumes semantic models that are application- or project-specific.
Semantic models consist of entity grammars, grammars inferred from a training corpus, and trained classifiers, among other data fill. The data fill powers a pipeline with rule-based processing, feature extraction, classification, and rationalization.
Like domain language models, semantic models (including ALMs) are generated by Nuance Experience Studio or Nuance Mix Tools.
In addition to models, both Krypton and NLE accept dynamic content in the form of wordsets. (In this context, dynamic means "loaded at runtime.") A wordset consists of one or more words/phrases in the application that can be applied to known entities in the models at runtime. For example, if the entity "PAYEE" is a placeholder in the model set, the dynamic entries to the entity might include "Visa", "Diner's Club", "Master Card", and any number of specific payees.
For information on referencing models and wordsets (artifacts) from your Dragon Voice application, see Triggering the Dragon Voice recognizer.
Starter packs to speed development
Starter packs accelerate development of natural language applications by providing developers and Nuance Professional Services with out-of-the-box recognition and semantic understanding capabilities. Starter packs minimize the need for upfront data collection, tagging, and building of acoustic models, language models, and semantic models. Starter packs are provisioned by Nuance and typically made available as part of your project in Nuance Experience Studio or Nuance Mix Tools. Consult Nuance for more information.
Profanity filter
Krypton can remove profanities from transcriptions of spoken text. To enable this feature, edit the Krypton's default.yaml file and add enableProfanityFilter in the protocol section. For example:
protocol:
defaultVersion: '1.0'
...
enableProfanityFilter: true
Custom pronunciations
You can add custom pronunciations to improve Krypton recognition of user speech in specific environments. You accomplish this by generating a DLM that includes a pronunciation file (also called a prons file) with words expressed in the IPA or XSAMPA phonetic alphabet. The words can be existing vocabulary or new vocabulary added with a dynamic wordset. General procedure:
- Create a pron file named _client_prons.txt.
- Include the file when generating a DLM.
- Load the DLM into a Krypton session.
Note: The custom pron feature is for speech scientists who are comfortable with phonetic alphabets. An alternative, non-technical way to specify unusual pronunciations is to use the wordset "spoken" option. See Using wordsets.
The custom pronunciation file defines specific words using a phonetic alphabet. Create the file following these rules and guidelines:
- Create a plain text file named _client_prons.txt. Encode the file with UTF-8.
- On the first line, specify the phonetic alphabetic used in the file (IPA or XSAMPA) followed by a Tab and a dot (.). The dot is the default phoneme separator. To change it, enter a character after the Tab.
- On each subsequent line, enter a word with one or more pronunciations. Separate all fields with Tabs. Each line must have at least one pronunciation for the word.
Get the symbols for each phonetic alphabet in the spreadsheet file,external-phonesets.tsv provided with each data pack in the lm/ directory.
- Be careful when including compound words or phrases in the pron file, as they can affect the pronunciation of the individual words within the compound. Specify compound words only when the phrase is unusual enough to be spoken as a whole.
The example shows a plan for custom prons:
| Word | Pron 1 | Pron 2 | Notes |
|---|---|---|---|
|
tomato |
t.ə.m.e.ɾ.o |
t.ə.m.ɑ.ɾ.o |
tomato, tomahto |
|
scone |
s.k.ɑ.n |
s.k.o.n |
scon, scone |
|
caribbean |
k.ə.ɹ.ɪ.b.i.n̩ |
k.æ.ɹ.ɨ.b.i.n̩ |
caRIBian, cariBEan |
|
herb |
h.ɚ.b |
ɚ.b |
herb, erb |
|
futile |
f.j.u.ɾ.l |
f.j.u.t.ɑɪ.l |
feudal, fewtile |
|
cinq a sept |
s.æ.ŋ.k.ɑ.s.ɛ.t |
sankaset (a word borrowed from French, meaning a 5-to-7 party) |
Here is the implementation for the example (the _client_prons.txt file):
IPA .
tomato t.ə.m.e.ɾ.o t.ə.m.ɑ.ɾ.o
scone s.k.ɑ.n s.k.o.n
caribbean k.ə.ɹ.ɪ.b.i.n̩ k.æ.ɹ.ɨ.b.i.n̩
herb h.ɚ.b ɚ.b
futile f.j.u.ɾ.l̩ f.j.u.t.ɑɪ.l
cinq a sept s.æ.ŋ.k.ɑ.s.ɛ.t
Include the _client_prons.txt file with other training material for a DLM, or as the only training file in the DLM.
Example: a banking DLM with training files including custom prons:
/banking-training
banking-sentences.txt
more-banking-sentences.txt
domain_entities.txt
_entity_PLACES.txt
_entity_NAMES.txt
_client_prons.txt
Example: a DLM containing only custom prons:
/prons-dlm
_client_prons.txt
Krypton automatically uses your custom prons when you trigger recognition with their DLM container. See Triggering the Dragon Voice recognizer.
Notes:
-
Custom pronunciations in preloaded DLMs are always applied. If different applications call your Krypton instance, they all use the preloaded custom pronunciations.
-
DLM weights do not apply to custom pronunciations: the pronunciations are applied globally without respect to the weight of their DLM containers.
- Recommended: load the custom pron DLM as early as possible so the pronunciations are in effect for all recognition turns.
