SSMs
This topic describes how to extract meaning from recognized text by combining statistical semantic models (SSMs) with traditional SRGS grammars and SLMs. You can do this for any language installed for Recognizer.
Although the combination of statistical language models (SLMs) and robust parsing technologies offers a flexible method for developing advanced natural language dialog applications, they still require that you write grammar rules for interpreting the spoken utterances. That can be problematic when expected responses to the prompt may range widely.
For example, suppose your application transfers a caller to a live agent when there is a problem with a bill. There may be too many different ways that callers express that they have a problem for an SRGS grammar to handle:
- “I think my bill total is wrong”
- “You overcharged me for January”
- “You sent the invoice to the wrong address”
With SSMs, grammar rules are optional: you can import grammars when parts of an utterance are best represented by a constrained SRGS grammar, but this is not required. Instead, an SSM evaluates the probable intended meaning by looking for certain key words and combinations of words. Always use an SSM with a confidence engine, which greatly improves the overall accuracy of the entire system.
For a suggested approach to the SSM creation and tuning process, see Process lifecycle for SSMs.
An overview of SSMs
A combined SLM/SSM is useful when it is hard to predict the exact phrases a caller might use, but the grammar can still assign one of a pre-defined set of labels based on combinations of key words that appear in the utterance.
A typical use for an SSMs is a call routing application, where a caller is routed to the correct destination based on the spoken utterance. In these applications, a caller may answer in different ways; but there is only a single slot to be filled, and that slot usually corresponds to the topic or the correct destination.
Other typical examples include customer service, and technical support. Here are some examples of dialogs that are well-suited for an SSM:
- One-step application routing:
System
How may I direct your call?
User
I want to check the status of my order.
System
I can help you with that. What is your order number?
- An SSM is also useful to cover prompts that ask about product items with long, formal names that callers will abbreviate in numerous ways:
System
What type of printer do you have?
User
It’s an LC three-sixty.
System
Let me check... yes, we have cartridges for the LC-360 color laserjet in stock.
- Finally, an SSM can be used in situations where callers do not know their precise goals, but where the application can predict categories for the goals:
System
Support hotline. What seems to be the problem?
User
I lost my wallet and my employee ID was in it.
System
Please hold while I transfer you to the security desk..."
A combined SLM/SSM works best with applications that classify a caller’s utterances in order to determine the application’s response.
How SSMs work
A statistical semantic model determines the meaning (or semantics) of recognized sentences. This meaning is calculated by models that are based on statistically-trained words and phrases.
The following diagram shows a simple example of how the SSM might rank the probabilities of a sentence that can be associated with multiple meanings:
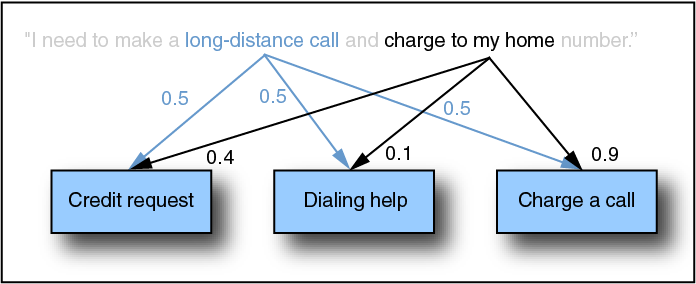
Here, the combination of words "long-distance call" narrows down the number of possible activities, while "charge to my home" is most likely to refer to a request to charge a call. Recognizer’s interpretation is weighted accordingly.
Training files
Like SLMs, SSMs are trained from XML-formatted training files. A training file contains sample sentences, their meanings, test sentences, and configuration parameters. During training, SSMs use patterns found in example sentences to assign meanings to words, and rank each meaning’s statistical possibilities.
As with an SLM, the quality of the training sentences determines the quality of the generated SSM. The training set for the SSM is likely to be a representative subset of the SLM training sentences. While this is not strictly necessary, it is often convenient to use the same real data if possible. See Data collection for training files and Data collection for SSM training files.
Once the SSM has been created, a confidence engine model for that SSM is also trained, using a separate training file. The training process is similar to an SSM: you create a training file (much simpler than an SSM training file), and submit the file to an iterative training tool. Again, the sample audio files used for the confidence engine training file are likely to be a representative subset of the SSM training sentences, if this is at all feasible.
For details on the training process for both SSMs and confidence engines, see Training files and Confidence engine models.
Data collection for SSM training files
Like all other natural language techniques, an SSM must be trained from transcribed sentences in an XML training file. Typically, you need at least 500 training sentences for each meaning to create an SSM, and difficult recognition tasks require far more—easily 2,000 sentences for a call routing application that asks an open-ended question, such as: "How may I help you today?". See Very large training files.
In addition, more sentences are needed for testing. The test set sentences must be independent of the training sentences. To create a large number of sample sentences for training and testing, use the following process:
- Define the categories of sentence meanings and the labels.
- Write questions that elicit enough information to apply a label to utterances.
- Collect example utterances in response to the questions.
- Label the example utterances with label names.
- Divide the sentences into training and testing data.
An early step of SSM training and data collection design is to define a list of needed labels. A label identifies a classification for an utterance. The needed number of labels is determined by the business requirements of the application.
Note: Fewer labels yield better accuracy. In general, the fewer labels, the better.
In call routers, for example, the labels indicate which agent pool or which automated system a caller is trying to reach. In technical support applications, the labels may be types of problems such as hardware, software, and billing.
There are three types of labels:
A direct label is a one-to-one mapping between a semantic category and a target action. For example, an application for a phone company may have a direct label for a DSL module. All caller utterances regarding DSL will be labeled "DSL" and will result in the caller being sent to the DSL portion of the application.
One common direct label is an "operator" label. All requests to speak to a live agent get mapped to this label, even if no operator transfer is available.
With intermediate labeling, semantic categories may share target actions. For example, caller requests for DSL repairs will get mapped to a "FixDSL" label. Caller requests to cancel DSL service will get mapped to a "CancelDSL" label. Both FixDSL and CancelDSL will lead to the same DSL portion of the call.
This extra layer of abstraction allows for flexibility. Future versions of the application can send the different labels to different portions of the application.
In the situation where the application wants to send FixDSL and CancelDSL to different portions of the application, a statement such as "I’m calling about my DSL" may be ambiguous. It may not be possible to map such an utterance to either FixDSL or CancelDSL. This utterance would get mapped to an ambiguous label, "DSL," where it might have one of the following results:
- An ambiguous label might lead to a directed dialog, such as: "You’re calling about your DSL. Do you want to request a repair, check a bill, or cancel the service?" This type of directed dialog is sometimes referred to as a "vague state," as it handles cases where a caller’s initial response was vague.
- An ambiguous label might return the application dialog to the initial question, perhaps prefaced with a prompt such as: "I need a bit more detail."
Since labels are a central component of any SSM, it’s important to set them up properly.
Make your label scheme as complete and efficient as possible. The labels need to cover user meanings thoroughly without having too many labels.
Some caller utterances may be ambiguous, and this affects application design and performance. If an utterance maps to two different labels, a follow-up question may be necessary. If an utterance maps to none of the labels, the caller may need to be reprompted with a more directed prompt, or to go to an agent.
To minimize such problems, the following strategies are recommended:
- Use the fewest labels possible to cover the application requirements fully.
- For vague or off-task utterances assign a special label, such as UNKNOWN. It is better to keep such utterances in the training to prevent similar utterances from being falsely classified.
- For ambiguous utterances, use a special label to let the application know that a follow up prompt is required. For example, if the utterance mentions a printer but not the type, you can use a PRINTER_MODEL_UNKNOWN label to trigger a follow-up question (“What type of printer?).
When designing labels, balance caller expectations with the rules and organization of the business.
For example, a telephone company might care about routing calls to three departments: Billing, Orders, and Repair. But if you train your SSM to discriminate only among these three, it will be difficult to have more specific dialogs with the caller. For example, your application might be limited to high-level confirmations (the names of the 3 departments) that the caller might reject because they are not specific enough:
|
System |
Please briefly describe your problem. |
|
User |
I have this weird kind of hum on my line. |
|
System |
I think I understand -- you need to have your line repaired, is that right? |
|
User |
No, it works fine but it makes noises! |
Limit the number of labels in your SSM by avoiding unnecessary labels that lead to a branch of the application already covered by another label. Each unnecessary label requires more training data and increases the likelihood of ambiguous classifications and lower confidence scores.
You can restrict the meanings used for a particular SSM by using the variable SWIInternalSSMMask. This variable enables you to use only a specified subset of available meanings, or to prohibit using a subset of meanings.
You can enable or disable a list of meanings from the grammar URI line, using the variable internalSSMMask; for example:
http://myServer.com/myGrammar.grxml?SWI.internalSSMMask=bank.ssm:1:bill,
payment,address | color.ssm:0:red,white
The value of SWI.internalSSMMask is defined as a series of specific masks separated by vertical bars:
SWI.internalSSMMask = SSMMask1 | SSMMask2 | …
Where each SSM specific mask has the following format:
SSMName:enableState:meaningName1,meaningName2, …
|
Element |
Description |
|---|---|
|
SSMName |
Name of the SSM, as it appears in the grammar wrapper xml file or the compiled grammar. This filename does not include path information. |
|
enableState |
Whether to include (1) or exclude (0) only the listed meanings. |
|
meaningName |
Meaning label in the SSM. The meaningName can include an asterisk (*) as a wildcard:
|
To use the following sensitive characters in the mask, you must precede them with the escape character "\": "|", ",", ":", "*"; for example:
Meaning\*1
Note: Note that because the programs acc_test and rec_test remove the escape character in the grammar URI, you need use double escape (\\) in your input test scripts.
Examples
Here are some examples of the mask format:
- bank.ssm:1: bill, payment, address |color.ssm:0: red, white
This line allows the three meanings "bill", "payment" and "address" in SSM "bank.ssm", and disallow two meanings "red", "white" in SSM "color.ssm".
- bank.ssm:1:bill,\*payment\*,\*address\*|color.ssm:0:red,white
This allows the meaning "bill", and all meanings that contain either "payment" or "address".
- bank.ssm:1:bill,account\:balance|color.ssm:0:red,white
If you have a meaning named "account:balance", escaping the : character.
The mask specified in the grammar URI is printed out in the call logs, using the MASK token, so that we can keep track of this feature in accuracy tests. For example:
TIME=20110216114732257|CHAN=0|EVNT=SWIloadRouteMask
|MASK='trained.ssm:1:agent||'|UCPU=453|SCPU=0
To include the mask information in diagnostic logs, set SSM_MEANING_MASK_TAG to ’yes’ in your config/defaultTagmap.txt. Upon success, SSM_MEANING_MASK_TAG prints out the set of meanings that conforms to the specified masks.
An application can use a meaning mask to allow or disallow a set of meanings based on caller input. For example, in the following dialog, we can allow only certain meanings:
|
System: |
Which service are you interested in? |
|
Caller: |
Balance Inquiry. |
|
System: |
I have a number of services, please choose one of the following: current account balance, |
A set of related meanings can be retrieved based on the caller’s initial query “Balance Inquiry”. These related meanings need be consistent with the choices in the short list. Suppose these meanings are "balance_report", "balance_check", and "credit_card", we can set a mask by using:
SWI.internalSSMMask=bank.ssm:1:balance_report,balance_check,credit_card
When the caller’s second utterance is recognized, we consider only the meanings specified in the mask.
We can also disallow meanings by using the mask, for example:
|
System: |
Are you interested in knowing your balance? |
|
Caller: |
No. |
|
System: |
Can you tell me what you are interested? |
|
Caller: |
I want to cancel my account. |
In this scenario, after the caller confirms that he is not interested in knowing his balance, we can disallow the most relevant meanings to the "balance" in the succeeding processing. Suppose these meanings are "balance_check", "balance_report", the mask is set as:
SWI.internalSSMMask=bank.ssm:0:balance_report,balance_check
Wrapper grammars
When developing an SSM, you will have to use wrapper grammars in order to link it with its associated SLM. There are two principal functions for wrappers:
- When training the confidence engine, the wrapper grammar groups the SSM and its related SLM (the .ssm, .fsm, and .wordlist files).
- When using the final SSM, the wrapper grammar adds the confidence engine model, grouping the .fsm, .wordlist, .ssm, and .conf files.
For details, see Using in applications (wrapper grammars).
Multiple, parallel SSMs
You can activate more than one SSM at the same time. Together, they are called parallel SSMs, because they operate simultaneously on the recognized sentences.
To assign values to multiple slots using SSMs, the alternative to specialized, parallel SSMs is to have a single, comprehensive SSM that classifies all meanings for the task. This might reduce the effort for creating the training file and generating the SSM (one training file, one set of sentences, one cycle of SSM generation and tuning), but it also has disadvantages: it is less modular and re-usable, and may require much more training data to achieve the same accuracy (a multiplication of permutations with the combined sentences, versus the sum of permutations for two SSMs).
For a more complete discussion of parallel SSMS, see Parallel SSMs.
Override grammars
When you use SSMs, you can create wrapper grammars to specify combinations of grammar files. The wrappers let you mix SSMs with other grammars.
You can also specify the priority of grammars in a wrapper, a feature known as override grammars because it gives some grammars precedence over others. Instead of activating the grammars in parallel, the wrapper activates them in order of precedence. For example, if a higher priority SRGS grammar has a successful parse at runtime, Recognizer would ignore a lower priority SSM. The SSM would then not be used unless the SRGS grammar failed to match.
You do not need override grammars when your training files are large and very representative of your meanings. However, they are very useful for:
- Fallback strategy: Providing an SRGS grammar to recognize predicted utterances, and an SSM as a fallback to capture unpredictable utterances.
- Performance strategy: Attempting recognition with an SRGS grammar first, because the CPU and memory costs are less. This is identical to the fallback strategy, but with a different purpose.
- Compensation strategy for smaller training files: Adding rules for interpretations (slot-value destination pairs) that are not well-represented in the training data set because of low frequency or small training set size.
- Dynamic strategy for a changing application: For example, you could use dynamic override grammars to add phrases that a caller might say in response to a temporary promotional commercial or to include new meanings that haven’t been trained yet.
- Tuning strategy: Add an SRGS grammar to an existing SSM to handle evolving application needs. For example, after deploying an SSM you might detect new utterances that are not anticipated by the SSM. Instead of re-writing and re-training the SSM, you could write an SRGS grammar to cover the new sentences. For this scenario, you might reverse the priority of the grammars: first attempt recognition with the SSM, then the SRGS.
- Fixing common errors that persist after you’ve trained the SSM: Generalizations of common errors in the training set are good candidates for override grammars. (However, long utterances in the training data set that are unlikely to occur again are not good candidates for override rules.)
- Personalization: For example, you could use caller-dependant, dynamic override grammars to cover phrases that are more likely for a specific caller.
- Commands: For example, you could add universal command phrases.
Override grammars are always optional. If used, you normally add them after adding interpretation features. The interpretation features improve the performance of the SSM classifier, while the override grammars improve the performance of the application. For information on interpretation features, see Feature extraction and ECMAScript. See Wrapping SSMs with override grammars.
